
在科技领域,一则重磅消息如平地惊雷般掀起轩然大波。9 月 23 日,英伟达(NVIDIA,NASDAQ:NVDA)与 OpenAI 携手宣布达成一项震撼业界的合作协议,计划为 OpenAI 构建下一代 AI 基础架构,部署至少 10 吉瓦的英伟达系统。这一庞大的系统将用于训练和运行 OpenAI 的下一代模型,实现超级 AI 的部署。与此同时,英伟达更是展现出破竹之势,计划在新系统部署期间向 OpenAI 投资高达 1000 亿美元(按当前汇率,约合人民币 7100 亿元),其第一阶段预计在 2026 年下半年正式上线。

根据双方达成的协议,OpenAI 将与英伟达紧密合作,成为其 AI 工厂增长计划的首选战略计算和网络合作伙伴。不仅如此,双方还将携手对 OpenAI 模型、基础架构软件以及英伟达的硬件和软件路线图进行深度优化。据悉,在未来几周内,英伟达和 OpenAI 将进一步敲定这新一轮战略合作的详细内容。
“这无疑是一个规模宏大的项目。” 英伟达 CEO 黄仁勋在周一接受 CNBC 采访时难掩兴奋地表示。他进一步解释道,10 吉瓦的功率相当于 400 万至 500 万张图形处理器(GPU)卡,这一数量几乎等同于英伟达今年全年的出货总量,且是去年出货量的两倍之多。
OpenAI 联合创始人兼 CEO 奥尔特曼(Sam Altman)也对此次合作寄予厚望,他强调:“一切的根源皆来自于计算。计算基础设施必将成为未来经济的基石,我们将借助与英伟达合作构建的强大基础设施,实现新的 AI 突破,并大规模地赋能个人与企业。”
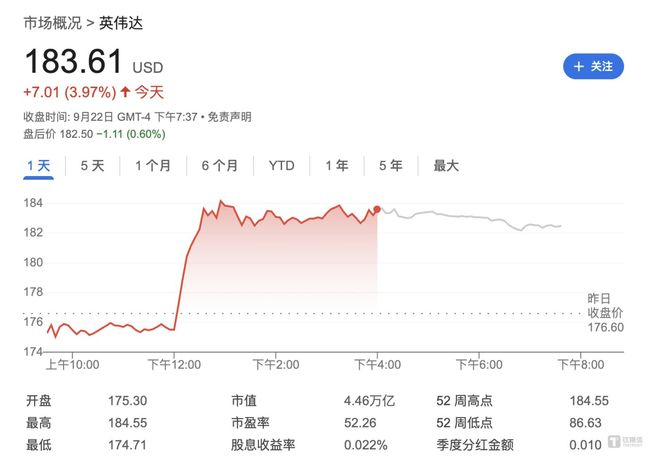
受此振奋人心的消息影响,9 月 22 日美股市场上,英伟达股价一路飙升,盘中一度涨超 4%。直至美股收盘,英伟达收涨逾 3.9%,成功创下历史新高,总市值也随之攀升至 4.46 万亿美元的惊人高度。
同时,这一消息的影响力如同涟漪般不断扩散,刺激着整个美股市场呈现上扬态势。周一当天,费城半导体指数收涨将近 1.6%;标普 500 指数收涨 29.39 点,涨幅 0.44%,报 6693.75 点,今年第 28 次创下新高;道琼斯工业平均指数收涨 66.27 点,涨幅 0.14%,报 46381.54 点,继续刷新收盘历史新高。
获超万亿支持,OpenAI 迈向 “算力帝国”
这项高达 1000 亿美元的投资合作将分阶段稳步推进。根据新协议,一旦双方就 OpenAI 收购英伟达系统达成最终协议,英伟达将率先投资 100 亿美元。在第一阶段,数据中心的能耗为 1 吉瓦,预计于 2026 年下半年完成部署,投资金额将依据当时的估值来确定。后续资金则会随着 GPU 部署使用量的逐步提升,逐渐向 OpenAI 支付,以此确保投资与实际建设进度保持同步。
而这座即将崛起的美国智能算力中心,将采用英伟达最新的 Vera Rubin 平台,用于训练和运行 OpenAI 的下一代模型,其终极目标是加速实现 “超级智能”。
早在今年 8 月,黄仁勋在财报电话会议上就曾向投资者透露,建设 1 吉瓦容量的数据中心,成本大约在 500 亿至 600 亿美元之间,其中约 350 亿美元将用于采购英伟达芯片和系统。以此估算,10 吉瓦的项目规模有望为英伟达带来 3000 亿 – 4000 亿美元的收入。
事实上,在此次合作之前,OpenAI 在短短一周内便已成功拿下与甲骨文、微软、博通等公司超过万亿元的投资合作。9 月 10 日,甲骨文股价单日暴涨 36%,创下 32 年来最大单日涨幅,这一惊人表现主要得益于其与 OpenAI 签署的一项为期 5 年、价值 3000 亿美元(约合人民币 2.1 万亿元)的 “天价” 云服务合同。9 月 11 日,微软与 OpenAI 悄然签署了一份非约束性谅解备忘录,为后者的公司重组亮起绿灯,同时重申二者云服务 “独占” 模式的终结,这也意味着微软将持续助力 OpenAI 应对高昂的算力成本。此外,据报道,OpenAI 还与博通合作开展自研 ASIC 芯片项目,预计明年即可投产,届时将主要应用于模型推理层面。加上此次英伟达的 1000 亿美元投资,OpenAI 正大步流星地朝着万亿 “算力帝国” 的目标迈进。
自 2022 年 ChatGPT 横空出世后,微软迅速跟进,在 2023 年将对 OpenAI 的算力和现金总投资追加至 130 亿美元。微软提供的强大算力支持,助力 OpenAI 在 AI 技术领域一路突飞猛进,而 OpenAI 的技术成果又被微软巧妙地纳入各项云服务产品中,实现了双方的互利共赢。如今,ChatGPT 每周的使用人数已接近 7 亿,其运行和开发对算力的需求堪称天文数字。就在昨天,奥尔特曼透露,未来几周将推出一些新的 “算力密集型” 产品。
在英伟达投资之前,OpenAI 在最近的第二轮融资中吸引了软银、微软等多家机构的百亿美元投资,公司估值也随之飙升至 5000 亿美元。另据 The Information 报道,OpenAI 预计到 2029 年将耗费 1150 亿美元,这一数字相较于该公司之前的估计大幅增加了约 800 亿美元。其中,对自有数据中心服务器芯片和设施的投资将成为其现金消耗的主要原因。
奥尔特曼表示,英伟达和微软已成为公司的 “被动” 投资者,同时也是 “最重要的合作伙伴”。他还满怀信心地称:“在接下来的几个月里,大家可以对我们抱有极高的期待。OpenAI 必须出色地完成三件事:其一,开展卓越的 AI 研究;其二,打造出深受人们喜爱并愿意使用的产品;其三,找到应对这前所未有的基础设施挑战的有效方法。”
黄仁勋则强调,英伟达的此次投资是 “对已宣布和签约的所有事项的有力补充”。他感慨道:“从第一台 DGX 超级计算机到 ChatGPT 带来的重大突破,英伟达和 OpenAI 在过去十年里始终相互砥砺前行。此次投资和基础设施合作标志着我们踏上了新的征程 —— 部署 10 吉瓦电力,为下一个智能时代提供强劲动力。”
对于此次合作,伯恩斯坦分析师 Stacy Rasgon 认为:“一方面,这有助于 OpenAI 实现其在计算基础设施方面的宏伟目标,同时也助力英伟达确保这些目标得以顺利达成。另一方面,过去人们曾提出的‘循环’问题,此次投资可能会使其进一步加剧。” 但 Requisite Capital Management 执行合伙人 Bryn Talkington 却持有不同观点,他认为这笔交易实际上意味着英伟达向 OpenAI 投资了 1000 亿美元,而 OpenAI 随后又会将这笔资金用于购买英伟达的产品,“这对黄仁勋而言,无疑是极为有利的”。
Doyle, Barlow & Mazard 律师事务所的反垄断律师 Andre Barlow 指出:“这笔交易极有可能改变英伟达和 OpenAI 的发展轨迹。OpenAI 在软件方面的领先地位,将进一步巩固英伟达在芯片领域的垄断地位。这或许会让英伟达在芯片领域的竞争对手,以及 OpenAI 在模型领域的竞争对手,更难以实现规模的扩大。”
据报道,预计到 2030 年,OpenAI 的研发投入(主要为算力成本)将接近其总收入的 50%,有望成为美国科技行业中在算力投入和研发投入方面最高的公司。
DeepSeek V3.1 模型采用国产算力,中美加速 AI 算力争夺
此次 OpenAI 与英伟达的投资合作消息传出,恰逢 DeepSeek – V3.1 – Terminus 版本发布数小时之后。9 月 22 日,DeepSeek 宣布线上模型完成升级,当前版本号为 DeepSeek – V3.1 – Terminus,该版本包含思考模型和非思考模式两个版本,上下文长度均为 128k,用户可在线体验。
据介绍,此次更新在保留模型原有能力的基础上,针对用户反馈的问题进行了针对性改进。其中,deepseek – chat、deepseek – reasoner 分别对应 DeepSeek – V3.1 – Terminus 的非思考、思考模式。同时,3.1 版本进一步优化了 Code Agent 与 Search Agent 的表现,非思考模型输出长度默认 4K,最大 8K,思考模型输出长度默认 32K,最大 64K。在使用价格方面,DeepSeek – V3.1 – Terminus 模型百万 tokens 输入(缓存命中)0.5 元,缓存未命中则为 4 元,百万 tokens 输出价格达 12 元。
与此同时,9 月 19 日,在华为全联接大会 2025 期间,华为技术有限公司与浙江大学联合发布了国内首个基于升腾千卡算力平台的 DeepSeek – R1 – Safe 基础大模型。据浙江大学计算机科学与技术学院院长、区块链与数据安全全国重点实验室常务副主任任奎介绍,在算力平台搭建过程中,团队首次成功实现基于昇腾千卡算力平台的千亿级参数满血版大模型安全训练,系统性地攻克了训练环境中的诸多关键问题,并构建了服务器间环境依赖同步、数据与权重共享、协同训练推理等一系列实用开发工具。目前,该模型已在多个社区全面开源。

任奎表示,测试结果显示,在 MMLU、GSM8K、CEVAL 等通用能力基准测试中,DeepSeek – R1 – Safe 相较于 DeepSeek – R1 的性能损耗在 1% 以内。
更早之前,DeepSeek 团队共同完成、梁文锋担任通讯作者的 DeepSeek – R1 推理模型研究论文,成功登上国际顶级期刊《Nature》(自然)杂志封面。文中指出,DeepSeek R1 的训练成本仅约 29.4 万美元(约合 208 万元)。目前,几乎所有主流的大模型都尚未经过独立同行评审,而这一空白 “终于被 DeepSeek 打破”。评审该论文的 Hugging Face 机器学习工程师 Lewis Tunstall 表示,R1 是首个经历同行评审的大型语言模型,这开创了一个非常值得欢迎的先例;俄亥俄州立大学人工智能研究员 Huan Sun 也称赞道,DeepSeek 自发布以来,几乎对所有在大语言模型中使用强化学习的研究都产生了深远影响。
事实上,随着 DeepSeek 引发的热潮,中美两国在 AI 算力争夺方面的竞争愈发激烈。而中国 AI 算力需求正以年均 300% 的惊人速度急剧增长。IDC 与浪潮日前发布的《2025 年中国人工智能计算力发展评估报告》指出,DeepSeek 凭借其先进的算法优化和高效的模型性能,激发了众多新应用场景的需求,有力地拉动了数据中心、端侧及边缘计算的应用发展。
全球计算联盟(GCC)秘书处 CTO 苗福友预测,未来两三年,国内 AIDC 建设将以每年 40% 以上的增速持续增长,随后增速将逐渐趋于平缓,预计到 2030 年前后,年增长率可能降至 10% 左右。据国家数据局报告显示,截至 2024 年底,中国算力总规模达 280EFLOPS(每秒百亿亿次浮点运算),其中智能算力规模达 90EFLOPS,占比 32%。这一算力水平相当于把全球 80 亿人同时转化为超算,每秒每个人要完成超过 3 千万次计算,其技术实力令人惊叹。有机构预测,2025 年中国智能算力规模预计增长超 40%。国家数据局局长刘烈宏表示,中国算力目前位居全球第二,仅次于美国。
目前,中国在用算力中心机架总规模超过 830 万标准机架,算力总规模达 246EFLOPS(EFLOPS 是指每秒进行百亿亿次浮点运算),位居世界前列;全国算力中心平均电能利用效率降至 1.47,创建国家绿色数据中心 246 个;工业、教育、医疗、能源等多个领域的算力应用超过 1.3 万个。
不过,另据 Epoch AI 的分析,美国拥有全球四分之三的 AI 超级计算机算力,而全球实际上仅有 12%的国家和地区具备 AI 算力。因此,随着 AI 算力基础设施产业的蓬勃发展,全球对于包括 GPU 在内的 AI 算力需求正与日俱增。
摩尔线程创始人兼 CEO 张建中近期表示,当下市场对 GPU 计算卡的需求极为旺盛,大概需要超过 700 万张 GPU 计算卡,才能支撑每天输出的生成式 AI 和 Agentic AI 技术能力。并且,未来 5 年,AI 算力需求仍将保持 100 倍的高速增长。但以每一片晶圆大概产出 20 – 30 片有效算力计算,中国仍存在 300 万张 GPU 卡的产能缺口,产能在短期内还难以满足需求。
张建中认为,从中短期来看,国内算力市场面临着智能算力短缺的困境。据悉,截至 2024 年 11 月,全球已投运的智算中心项目近 150 个,在建和规划建设的智算中心近 100 个,但据浪潮人工智能研究院测算,中国智算中心平均算力利用率仅为 30%。
中信建投研报称,华为最新公布了一系列即将上市和规划中的新品,如昇腾 950PR / 昇腾 950DT、昇腾 960 和昇腾 970 三个系列产品,将分别于 2026 年第一季度和 2026 年第四季度,以及 2027 年第四季度、2028 年第四季度上市。同时,华为发布的 Atlas 950 超节点,支持 8192 张基于 Ascend 950DT 的昇腾卡,柜间采用全光互联,总算力得到大幅度提升,上市时间为 2026 年第四季度。因此,预计 9 月 – 10 月国内 AI 算力需求有望回暖,此外,对于国内云服务厂商也应予以重视。
“我们可以想象,如今中国所有晶圆制造工厂的产能总和,都不及需求量的十分之一。所以,如果国产 GPU 想要实现发展,对于半导体生产制造而言,我鼓励并呼吁整个产业界尽快向先进技术转型,尽快让自己的工厂和产品具备生产及评估的能力。” 张建中提到,当前国产 GPU 芯片的制造端主要面临三方面困境,即国际高端芯片禁运、高端 HBM 存储限售以及先进工艺制程限制。
据 SEMI 统计,预计到 2030 年,在 AI、物联网、机器人等技术的强力助推下,全球芯片产业规模将突破 1 万亿美元。其中,中国 AI 芯片市场规模可能超过 1.3 万亿元,届时中国 AI 产业及相关行业的价值将高达 10 万亿元人民币。